
January // February 2024 Progress Update
Combinatorial discoveries

At the close of 2023, we completed the experimental work for our largest partial reprogramming screen to date. In January, we received the resulting sequencing reads and were elated to find that it worked perfectly.
We’ve spent the past two months extracting insights from these data and preparing follow up experiments to test new reprogramming factor sets based on the results. In parallel, we’ve begun laying the groundwork for our Metabolism program by onboarding hepatocytes to the Discovery Engine.
A few numerical highlights:
>10X more reprogramming factor sets tested than our prior largest experiment
>2M cells profiled, 10TB+ of raw sequencing data generated
+3 team members
2X reduction in the time from in silico reprogramming predictions to experiment ready libraries
+1 cell types demonstrated for our cell genomics chemistry & cell age prediction models
1st rejuvenating sets nominated

People
We welcomed several talented new members to the team at the start of the year:
Nick Bernstein joined as a Senior Data Scientist on our Predictive Modeling team
Justin Juang joined as a Research Associate on our Immunology team
Megan McMaster joined as a Laboratory Operations Manager
Our Discovery Engine delivered the largest reprogramming screen to date
By the numbers, we captured more than 2 million cell profiles treated with thousands of partial reprogramming factor sets. This represents >50X more reprogramming sets tested than field prior to NewLimit’s founding and >10X more than in our previous largest experiment. By cell count, this single experiment is in the same range as the 10 largest datasets in the CZI Census compendium of single cell genomics data.
This experiment represents the first full cycle of our Discovery Engine. We trained models on prior screens, predicted the results of reprogramming interventions, and used those predictions to design our largest experiment yet. We believe this synergy of atoms & bits will enable us to search through the massive space of reprogramming factor sets to discover new medicines.
Large datasets emerging from our Engine are only valuable if they lead to biological insights. We were heartened to find that this latest screen revealed new sets of factors that reprogrammed cell age and function. We also found that our Engine reproduced prior reports of reprogramming effects on cell fitness, confirming the technical validity of our approach. We’re excited to evaluate these new factor sets in the coming months to see which of them make old primary cells act young.

Reading epigenetic states in a new cell type
We built our Discovery Engine to be largely cell type agnostic. Our reprogramming factor delivery tools, single cell profiling chemistries, and predictive models are not tied to any one lineage. Nonetheless, we had not challenged our Engine to adapt to a new cell type until January this year.
We launched our Metabolism program at the end of 2023 and began work to onboard hepatocytes to the Engine. In early experiments this January, our Single Cell Genomics team demonstrated that our existing cell profiling chemistries were capable of generating high quality data in hepatocytes, on par with the best published data in the academic literature. Even with a modest data corpus from our first experiment, our Predictive Modeling team found that we can reliably predict cell age from hepatocyte profiles.
These experiments are the first time we actually demonstrated that components of our Engine are cell type agnostic. Here alone, we showed that both our genomics chemistry and predictive models are transferable. By the end of the quarter, we’re optimistic that we’ll demonstrate the remaining components in hepatocytes as well.

Ensuring reproducibility
Functional genomics experiments like we run with our Discovery Engine can suffer from reproducibility challenges. From day one, we’ve been focused on ensuring that our results can be replicated time and again through the use of rigorous operating procedures, standardized parts, and a set of internal controls.
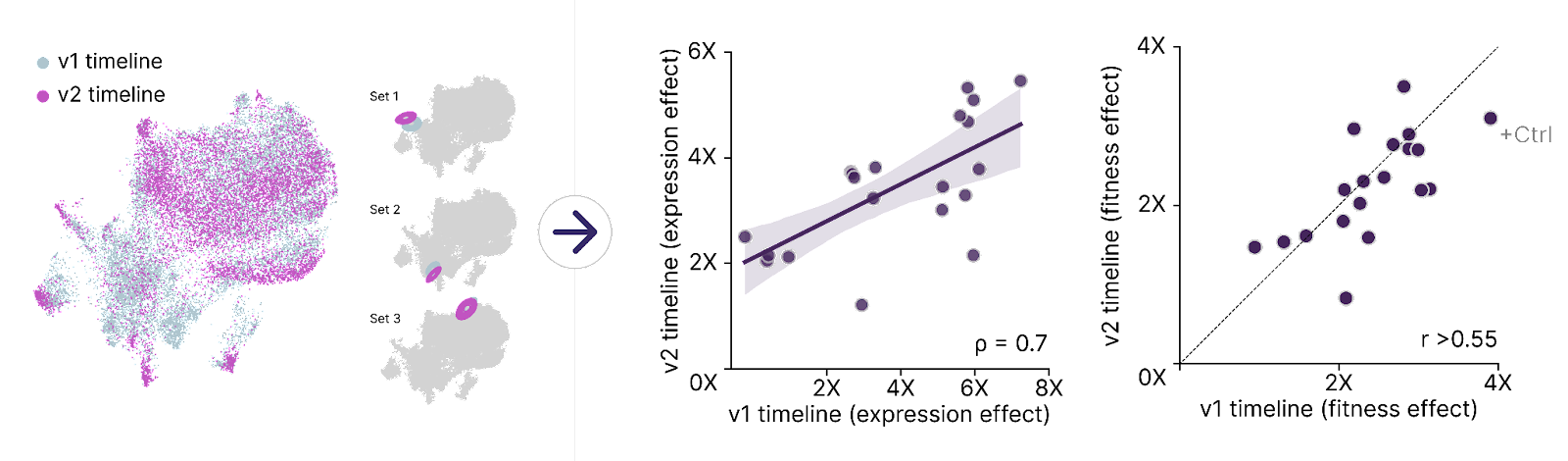
We recently had the opportunity to put the reproducibility of our Engine to the test when our Epigenetic Editing team found a way to shorten the timeline of our screens by 40%. We’re always excited by process improvements that can help us accelerate discovery, but it wasn’t immediately clear if the new approach would be as robust as our previous system.
We were pleased to find that the process we’ve built ensured that not only was each timeline reproducible across independent experiments, but the effects we observed were consistent even across these distinct experimental conditions.
Results like this give us confidence that our Engine is tuned and reliable.
Join us
We continue to recruit talented scientists, engineers, and operators. Please reach out if you’re excited by our mission to develop reprogramming medicines for aging!
