
May // June 2025 – Progress Update
Therapeutic pleiotropy

Our third summer at NewLimit headquarters has arrived. We’ve been making good use of the additional daylight in our new lab space.
A few highlights from our output:
+3 TF sets with pre-clinical efficacy in animal models of liver disease
+11 TF sets that restore youthful function in aged T cells
+>4000 TF sets tested across hepatocytes and T cells
100X increase in compute efficiency for reprogramming payload design models
>60% increase in hit discoveries in active learning campaigns
People
We’re excited to welcome several new members to the NewLimit team.
Ron Hause is joining as our Head of Computational Sciences leading our Computational Biology and Predictive Modeling efforts. Ron previously served as SVP and Head of AI at Shape Therapeutics, helping bring RNA medicines from the whiteboard toward the clinic.
Ron began his career in adoptive cell therapy, contributing to the development of Breyanzi and leading predictive modeling at Juno, Celgene, and BristolMyersSquibb. Ron's academic training began with a PhD in Genetics at the University of Chicago and culminated in a Damon Runyon postdoctoral fellowship under genomics pioneer Jay Shendure at the University of Washington. He brings over 15 years of experience at the intersection of statistical genomics, machine learning, and therapeutic development to help scale our computational capabilities.
We’re excited for Ron to help us bridge the gap between early discovery and therapeutic development.Ryan Theisen joined our team earlier this year as a Senior Machine Learning Scientist. Ryan previously developed generative models for small molecule design at Harmonic Discovery. In his academic training, Ryan performed celebrated research on model ensembling and completed a PhD in Statistics at UC Berkeley.
Michael Herschl joined our Functional Genomics team as a Scientist. Michael recently completed Ph.D. training at UC Berkeley and the Arc Institute where he developed pooled screening systems for epigenetic editing.
Nehal Hedge joined our Functional Genomics team as a Research Associate. Nehal started her career at Pragma Bio and completed her Bachelor’s degree at the University of Washington.
Restoring youthful function in multiple dimensions
The premise of NewLimit is that aging leads to a decline in cell function that contributes to diverse pathologies. If we’re able to restore youthful function in old cells, we imagine this could likewise help treat multiple diseases and quality of life impairments that arise with age.
We previously discovered reprogramming payloads that restored youthful gene expression in old hepatocytes and formulated these payloads into prototype medicines. Earlier this year, we demonstrated that our prototype medicines could rescue function in one animal model of liver disease. Prototype medicines that reverse cell age should be effective across more than just one of these functional dimensions.
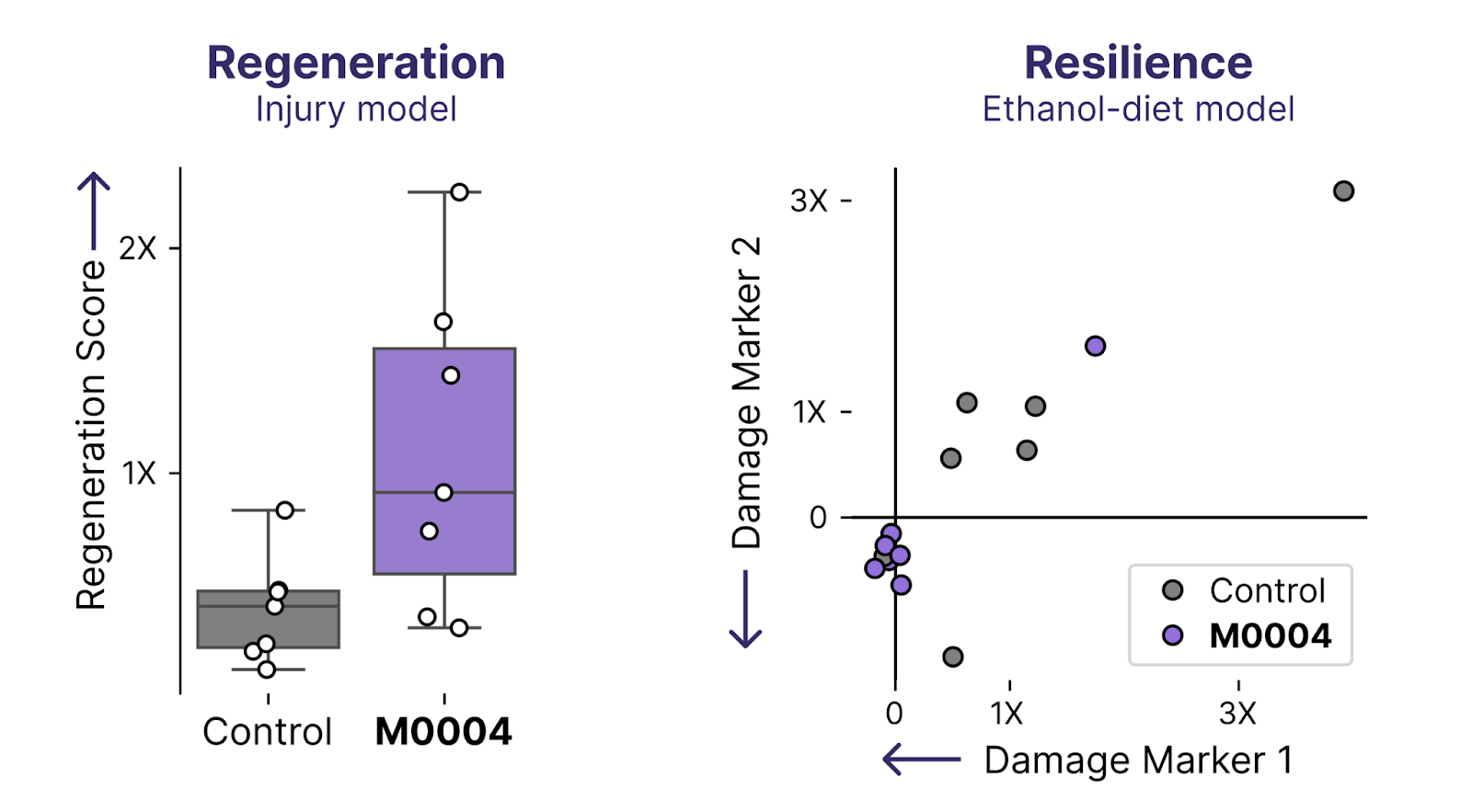
This summer, we explored whether these prototype medicines could restore youthful function in multiple disease models. If a payload can restore more than one youthful function, it suggests that underlying features of age have been reversed. We were excited to discover that a prototype medicine emerging from our Discovery Engine screens (M0004) not only improves hepatocyte regeneration, but also appears to restore youthful resilience to damage from alcohol.
These data are still preliminary, but deepen our conviction that it’s possible to restore youthful function across multiple dimensions.
Generative design of reprogramming payloads
There are ~10^16 possible combinations of TFs that might reprogram cell age. This represents ~10,000X the number of stars in the Milky Way galaxy. No matter how sophisticated our experimental systems become, we will never test all of them.
From our earliest days, NewLimit has been developing an artificial intelligence (AI) system to search this space by performing reprogramming experiments in silico. Earlier this year, we demonstrated that our in silico reprogramming models could predict reprogramming effects 2X better than the state-of-the-art in the broader field. These models allowed us to answer the question: What will happen if we reprogram old cells with TFs X, Y, and Z?
Designing the optimal payload to reprogram cell age requires us to ask a related, but different question: What combination of TFs is most likely to reverse cell age, while preserving cell type? It turns out that mathematically, this latter question is a generative problem. Exhaustively predicting the effect of all possible reprogramming payloads with our models is possible, but quite expensive – >$1M! We therefore need an efficient algorithm to design payloads.
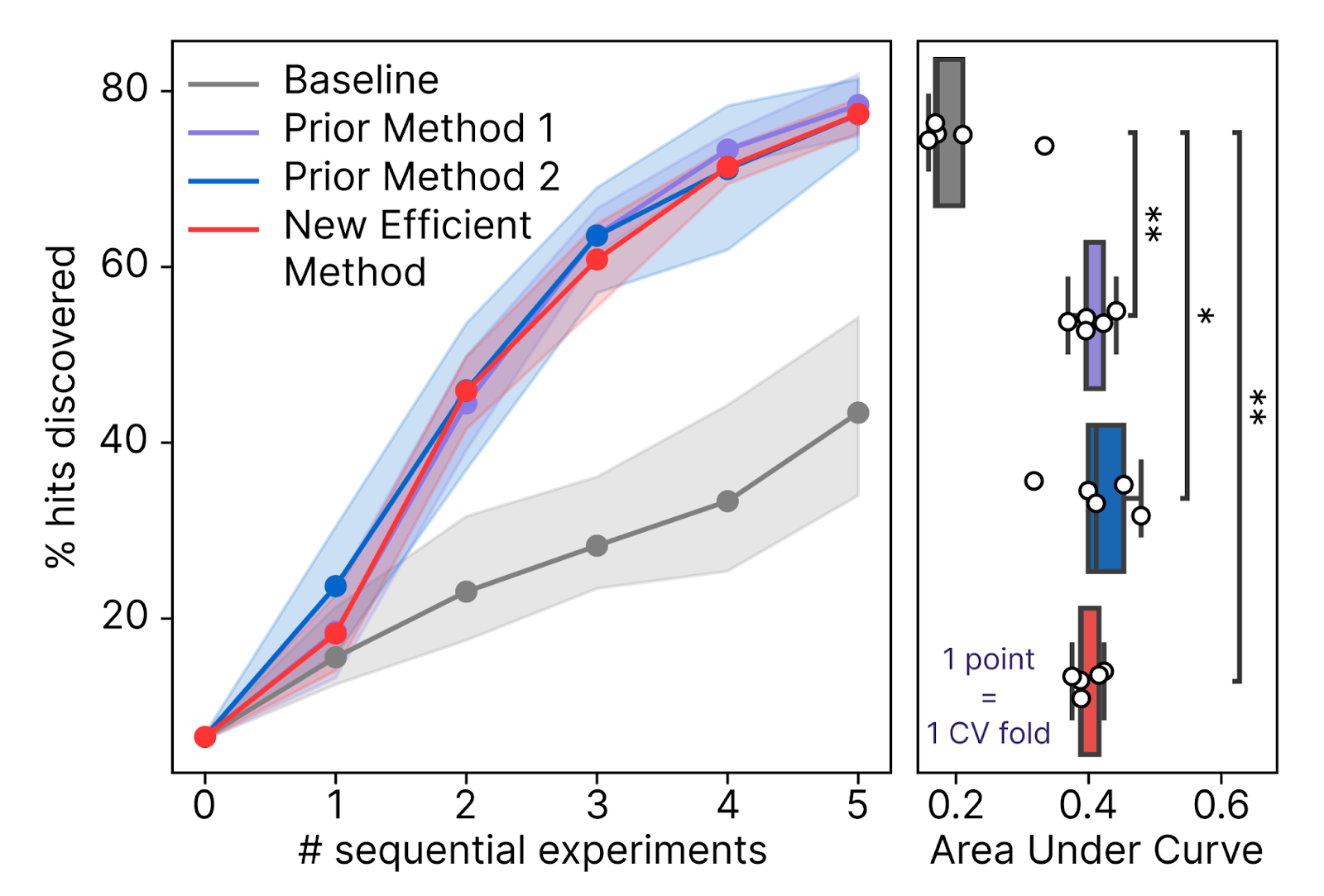
Our Predictive Modeling team overcame this bottleneck by developing a Bayesian generative process that allows us to design optimal payloads with >100X less compute than before. This approach not only allows us to efficiently deploy our models into our production Discovery Engine experiments, but also enables us to search even larger hypothesis spaces in the future, including the design of synthetic TFs.
The true test of these methods is whether they can accelerate our reprogramming discoveries by recommending new hypotheses to test after each screening experiment. This is akin to an active learning or Bayesian optimization setting. We’ve now demonstrated that using our new payload design algorithms can increase our discovery rate by >60% in a simulated campaign.
Production-grade reprogramming screens
The data corpus that fuels our in silico reprogramming models is the result of relentless experimental progress in our Discovery Engine. When we started two and a half years ago, every element of our technology had to be built from scratch. Nothing was optimized, and we had yet to even determine which parameters were most critical to tune. We couldn’t execute as many experiments as we desired, and we discovered many quality control challenges.
Each experiment has yielded lessons that allowed us to improve on both of these metrics. Quarter over quarter, we’ve continued to increase the number of screens we can execute. Alongside an increase in throughput, we’ve instrumented our process end-to-end to reduce error rates. There was no singular update that explains our progress in these dimensions, but rather a process of continual improvement that led to countless small changes. That process itself was only possible due to the efforts and ingenuity of our team.
This summer, we’re proud to complete the quarter with our highest throughput and lowest quality control failure rate on record. We’re able to turn investments of time and resources into more discoveries than ever.

Our most recent screens have contributed thousands of new reprogramming payloads to our growing data corpus. We’ve now tested >700X as many payloads as the rest of the field combined to our knowledge.
We believe the scale of this data corpus is one of the key reasons we’ve been able to build performant in silico reprogramming models. Since our initial report of data scaling laws for reprogramming, we’ve found that scaling continues in the larger data regime. These results give us confidence that our investments in experimental throughput and quality will continue to yield dividends.

We’re at the beginning
All of us at NewLimit are excited by the data that now readily emerge from our models and laboratory. Alongside our recent fundraising, we’re expanding to build reprogramming medicines across even more therapeutic areas. Nonetheless, we’re still at the beginning of the story. Our impact will only grow from here.
If you’re motivated to build medicines that add healthy years to every human life, please consider joining our team for the upcoming chapters.
